网络IO,会涉及到两个系统对象,一个是用户空间调用IO的进程或者线程,另一个是内核空间的内核系统。
五种IO网络模型
阻塞I/O
一个典型的读操作流程
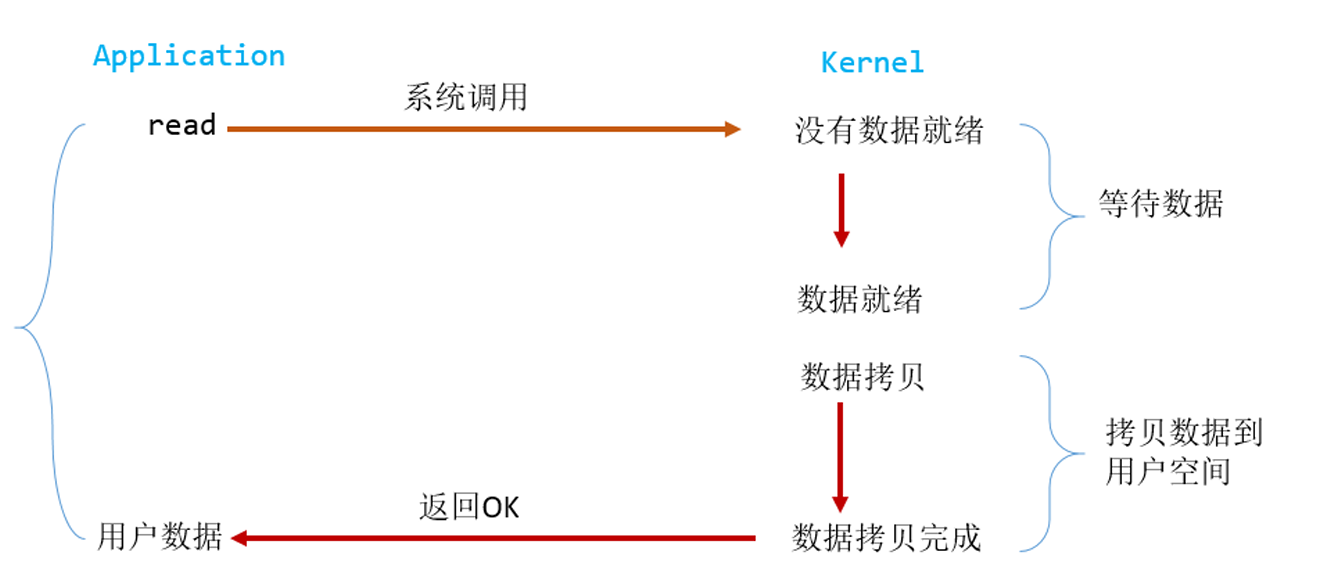
阻塞IO
用户进程进行了read系统调用后,用户进程会被阻塞。kernel开始准备数据,直至所有的数据到达之后,它会将数据拷贝到用户内存,然后返回结果,解除用户进程block的状态。阻塞IO的特点就是在等待数据和拷贝数据阶段,用户进程都处于block状态。
实际上,除非特别指定,几乎所有的IO接口(包括socket接口)都是阻塞型的。在线程阻塞期间,线程将无法执行任何与运算或响应任何的网络请求。简单的改进方案是使用多线程(或多进程),让每个连接都拥有独立的线程,这样任何一个连接的阻塞都不会影响其它的连接。
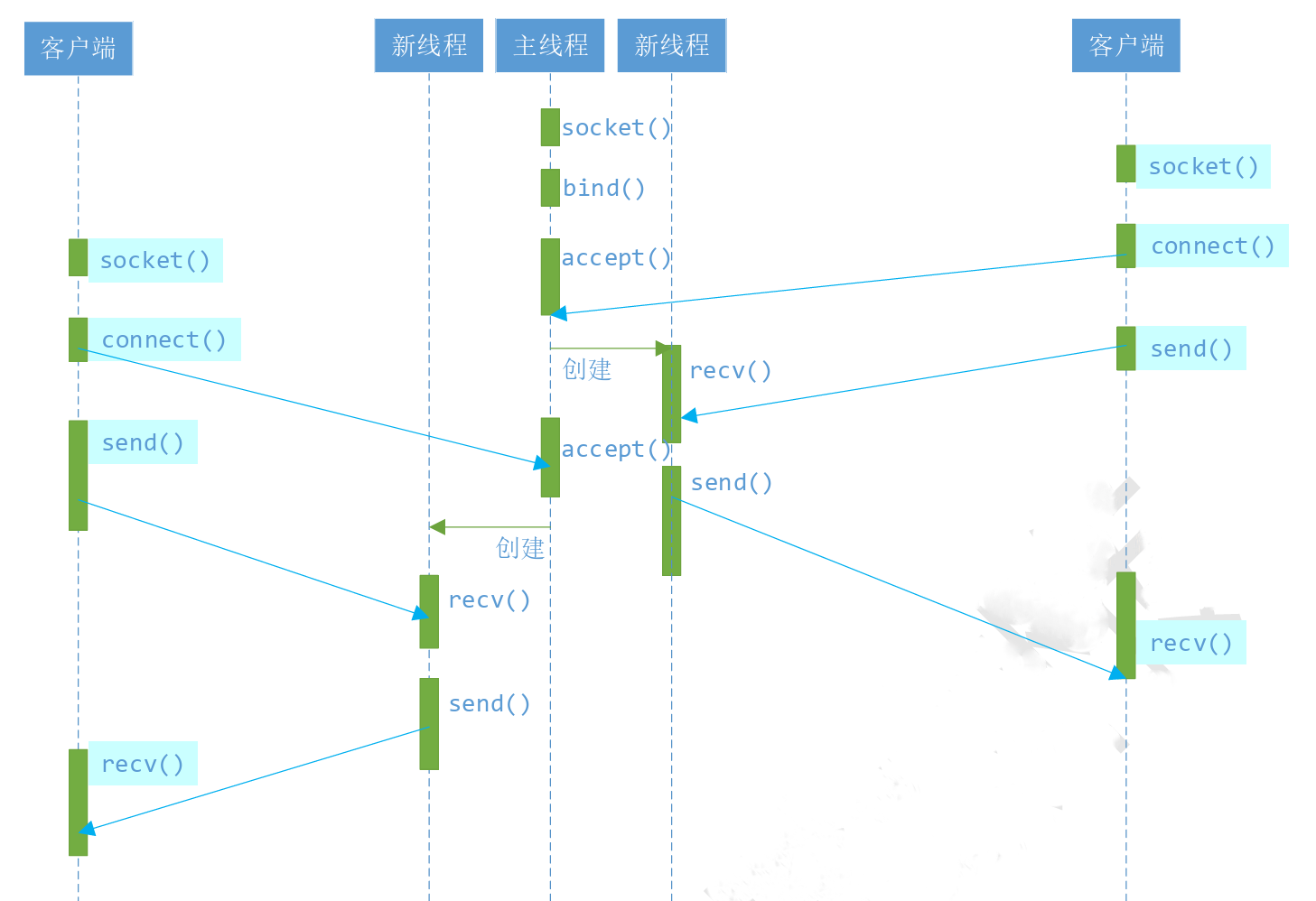
线程的服务器模型
执行完bind和listen后,os开始在指定的端口监听所有的连接请求,如果有请求,则将该连接请求加入请求队列。调用accept接口正是从请求队列中抽取第一个连接信息,如果没有连接,accept将进入阻塞状态直到有请求进入队列。
多线程服务器模式可以解决同时和多客户端交互的问题,但是当客户端太多时,多线程模式会严重占据系统资源,可能造成系统迟缓。可能考虑使用线程池或连接池。线程池旨在减少创建和销毁线程的频率,维持一定合理数量的线程,并让空闲的线程重现承担起新的执行任务。连接池维持连接的缓冲池,尽量重用已有的连接,减少创建和关闭连接的频率。这些技术在一定程度上缓解了频发调用IO接口带来的资源占用,但是池始终有其上限,当请求大大超过上限时,池构成的系统对外界的相应并不比没有池的时候效果好多少。面对大规模的服务请求,多线程模型会遇到瓶颈。
非阻塞IO
可以通过设置socket使其变为non-blocking。读流程如下:
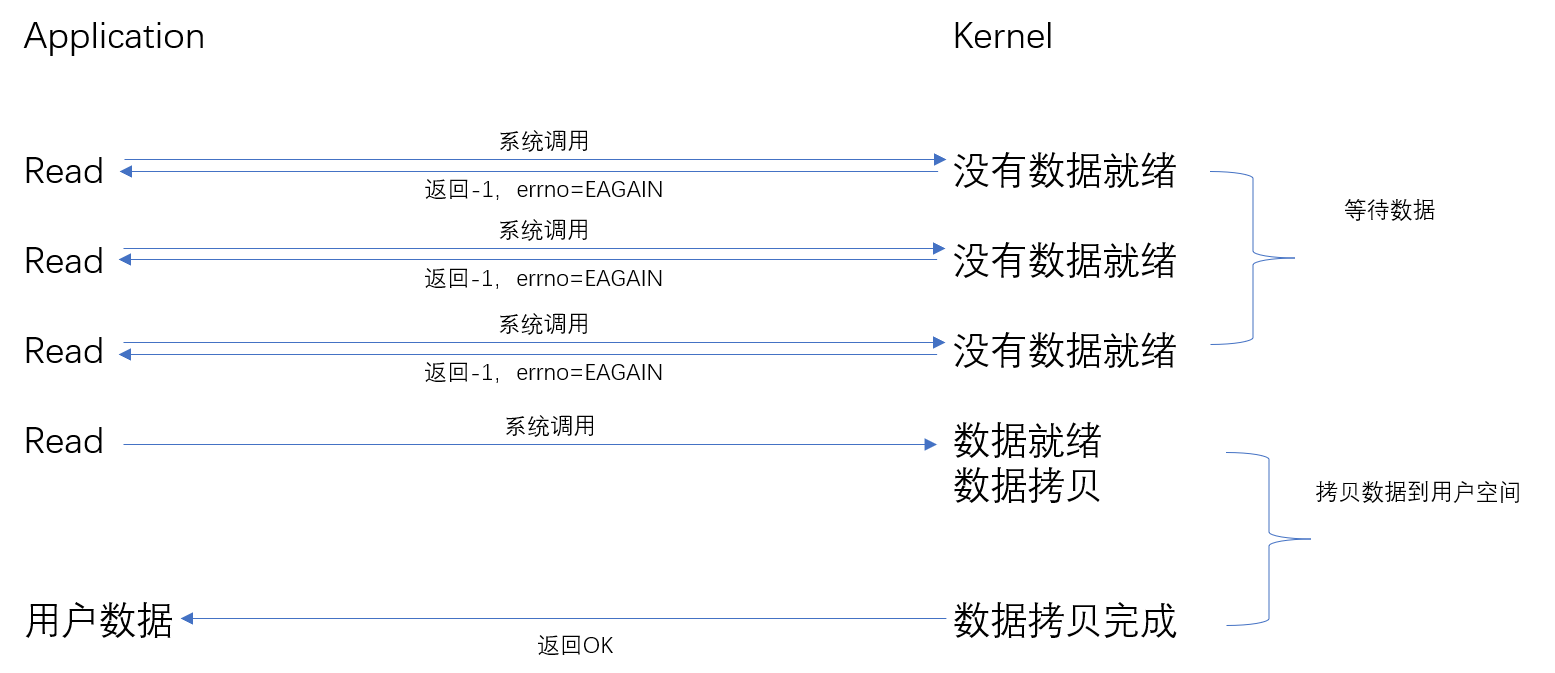
从用户进程角度讲,他发起一个read操作时,并不需要等待,而是马上得到了一个结果。用户进程判断结果是一个error时,他可以再次发送read操作。一旦kernel中的数据准备好了,并且再次收到了用户进程的system call,它将数据拷贝到用户内存,返回。用户进程需要不断的主动询问kernel的数据是否准备好。
recv返回值大于0,表示接受数据完毕,返回值是接收到的字节数
recv返回值0,表示连接正常断开
recv返回值-1,且errno等于EAGAIN,表示recv操作还没执行完成
recv返回值-1,且errno不等于EAGAIN,表示recv操作遇到系统错误errno
使用下面的函数可以将某句柄fd设为非阻塞状态
fcntl(fd, F_SETFL, O_NONBLOCK);
设置为非阻塞模式后,服务器端根据返回值判断数据是否准备就绪,并通过循环操作,使用一个线程解决和多客户端通话的问题
#define WIN32_LEAN_AND_MEAN //windows.h和WinSock2.h有宏定义冲突,导致WinSock2.h必须要在windows.h前引用,定义该宏后可不用强制位置
#define _WINSOCK_DEPRECATED_NO_WARNINGS
#include<windows.h>
#include<WinSock2.h>
#include<iostream>
#include<vector>
#pragma comment(lib, "ws2_32.lib") //method_1
int main()
{
WORD ver = MAKEWORD(2, 2);
WSADATA dat;
WSAStartup(ver, &dat); //Windows socket网络环境的启动函数,需要引入ws2_32库文件,可以使用method_1,也可以在属性界面链接器的输入选项添加依赖项
//1.创建socket
std::vector<SOCKET> client_socks;
SOCKET sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP); //地址系列规范,套接字规范,使用的协议
//2.绑定地址
sockaddr_in server_addr = {};
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(6666);
server_addr.sin_addr.S_un.S_addr = INADDR_ANY; //代表本机所有地址
int ret = bind(sock, (sockaddr*)&server_addr, sizeof(sockaddr_in)); //若成功返回0
if (SOCKET_ERROR == ret)
{
std::cout << "绑定错误" << std::endl;
}
//3.监听端口
ret = listen(sock, 5); //第二个参数为挂起的连接队列的最大长度,若成功返回0
if (SOCKET_ERROR == ret)
{
std::cout << "监听错误" << std::endl;
}
//4.接收客户端连接
sockaddr_in client_addr = {};
int len = sizeof(sockaddr_in);
char buf[] = "hello, i'm server";
char recv_buf[128] = {};
unsigned long mode = 1; // 阻塞模式设置为0就可以了
int result = ioctlsocket(sock, FIONBIO, &mode);
while (true)
{
SOCKET client_sock = accept(sock, (sockaddr*)&client_addr, &len); //accept函数返回一个新的套接字来和客户端通信,sockaddr和sockaddr_in所代表的意义一样,字节大小也一样,只不过sockaddr_in是后面创建的,之前的接口没有更改
if (INVALID_SOCKET == client_sock)
{
if (WSAGetLastError() != WSAEWOULDBLOCK)
{
std::cout << "连接客户端错误" << std::endl;
break;
}
}
else
{
std::cout << "客户端:" << inet_ntoa(client_addr.sin_addr) << "连接成功" << std::endl;
unsigned long mode = 1; // 阻塞模式设置为0就可以了
int result = ioctlsocket(client_sock, FIONBIO, &mode);
client_socks.push_back(client_sock);
//5.发送数据
int buf_len = send(client_sock, buf, sizeof(buf), 0); //如果未发生错误, send 将返回发送的总字节数,该字节数可能小于 len 参数中请求发送的数量
if (SOCKET_ERROR == buf_len)
{
std::cout << "发送错误" << std::endl;
}
}
for (size_t i = 0; i < client_socks.size(); ++i)
{
int buf_len = recv(client_socks[i], recv_buf, 128, 0);
if (buf_len > 0)
{
std::cout << "我是客户端:" << inet_ntoa(client_addr.sin_addr) << ",发送的信息是:" << recv_buf << std::endl;
}
else if(SOCKET_ERROR == buf_len)
{
if (WSAGetLastError() != WSAEWOULDBLOCK)
{
std::cout << "接收信息错误:" << WSAGetLastError() << std::endl;
client_socks.erase(client_socks.begin() + i);
break;
}
}
}
}
//6.关闭套接字
closesocket(sock);
WSACleanup();
return 0;
}
上述方法可以在单个线程内实现对所有连接的客户端的交互。但是循环调用recv大大增加了cpu的占用率;此外,在这个方案中recv更多的是起到检测操作是否完成的作用,实际os提供了更为高效的检测接口,例如select多路复用模式,可以一次检测多个连接是否活跃。
多路复用IO
也被称为事件驱动IO。基本原理就是select/epoll等函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
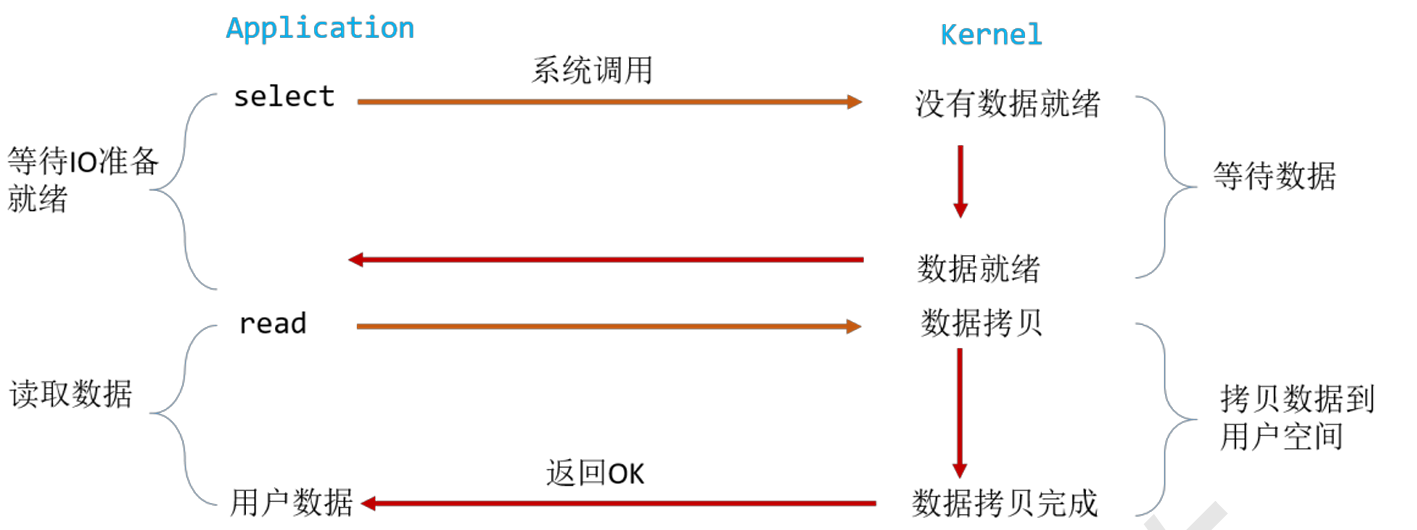
用户调用了select,整个进程都会被block,同时kernel会监视所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作。但是,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟更大。select/epoll的优势在于能处理更多的连接。
这种模型的特征在于每一个执行周期都会检测一次或一组事件,一个特定的事件会触发某个特定的响应,称为事件驱动模型。但是select接口不是实现事件驱动的最好选择,因为当需要检测的句柄值较大时,select接口本身需要消耗大量时间去轮询各个句柄。其次,该模型将事件探测和事件响应夹杂在一起,一旦事件响应的执行体庞大,则对整个模型是灾难性的。因为庞大的执行体1将直接导致执行体2迟迟得不到执行,并在很大程度上降低了事件探测的及时性。